Every alert management capability. One platform.
AlertOps centralizes signal ingestion, correlation, routing, and escalation in a single system. 200+ integrations. No context switching.
One Incident From 14 Alerts. Every Time.
Your Datadog, Prometheus, and CloudWatch instances are firing independently on every symptom of the same failure. AlertOps ingests every signal, normalizes it, and runs OpsIQ Smart Correlation so your engineers see one actionable incident instead of 14 screaming alerts from three different tools.
- Cross-tool correlation across all 200+ monitoring and observability sources
- 73% alert noise reduction engineers respond to incidents, not storms
- Deduplication, suppression, flap detection, and maintenance window controls
The Right Alert Reaches the Right Engineer Before the Second Symptom Fires
Intelligent routing means a SEV-1 from Datadog at 2am reaches the right SRE via voice call, not a Slack message they will see at 9am. AlertOps routing logic is severity-aware, source-aware, and schedule-aware configured once, runs forever.
- Severity-based, source-based, and schedule-aware routing with no manual rule maintenance
- API-first and webhook-ready for any monitoring source not natively integrated
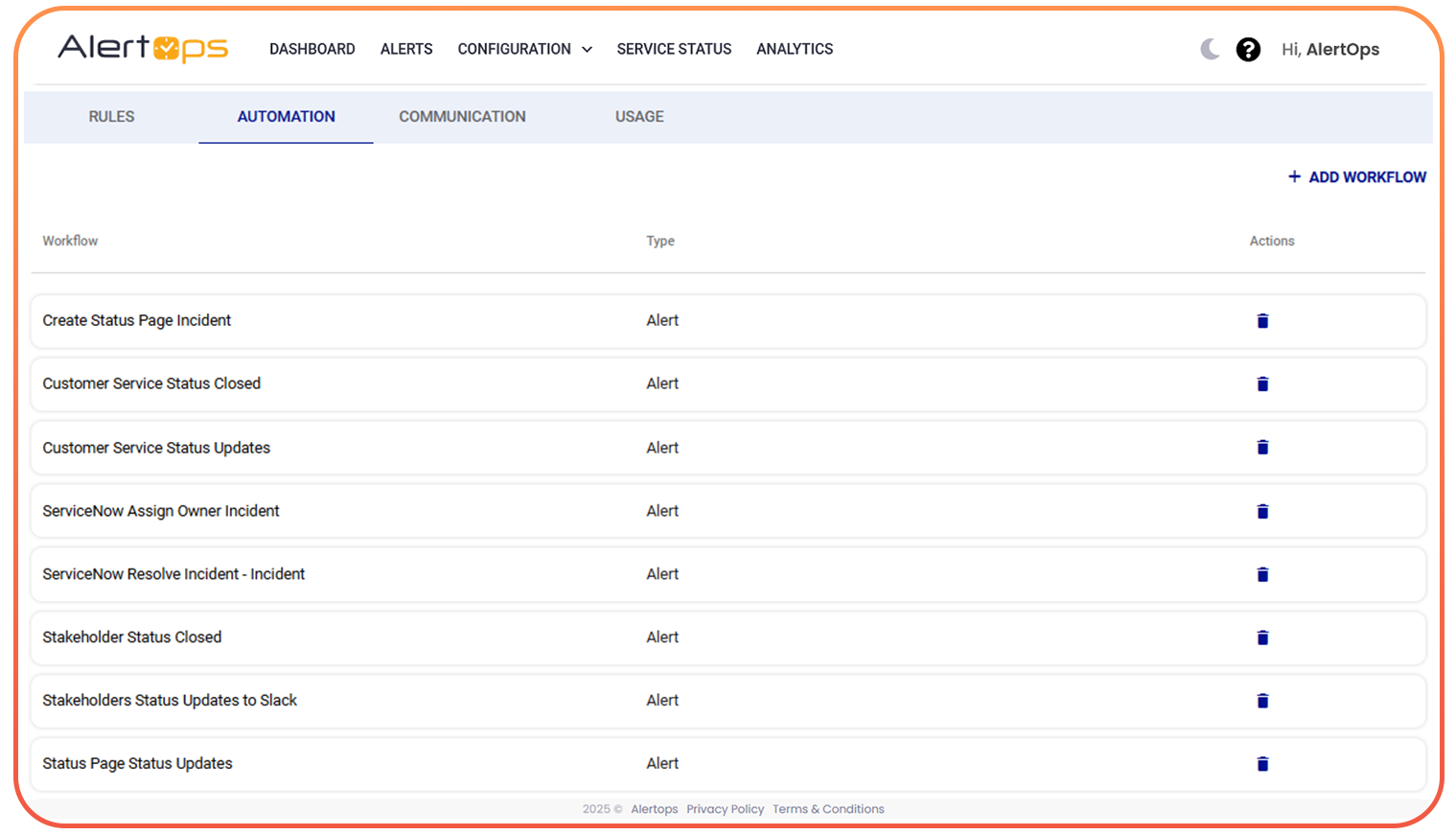
- Alert workflow automation: define once, AlertOps runs it for every matching signal
Every Engineer Reached Via the Channel That Actually Gets Their Attention
A P1 needs a phone call. A warning can go to Slack. AlertOps delivers the right alert through the right channel with the right content OpsIQ-enriched context so engineers arrive informed and ready to resolve.
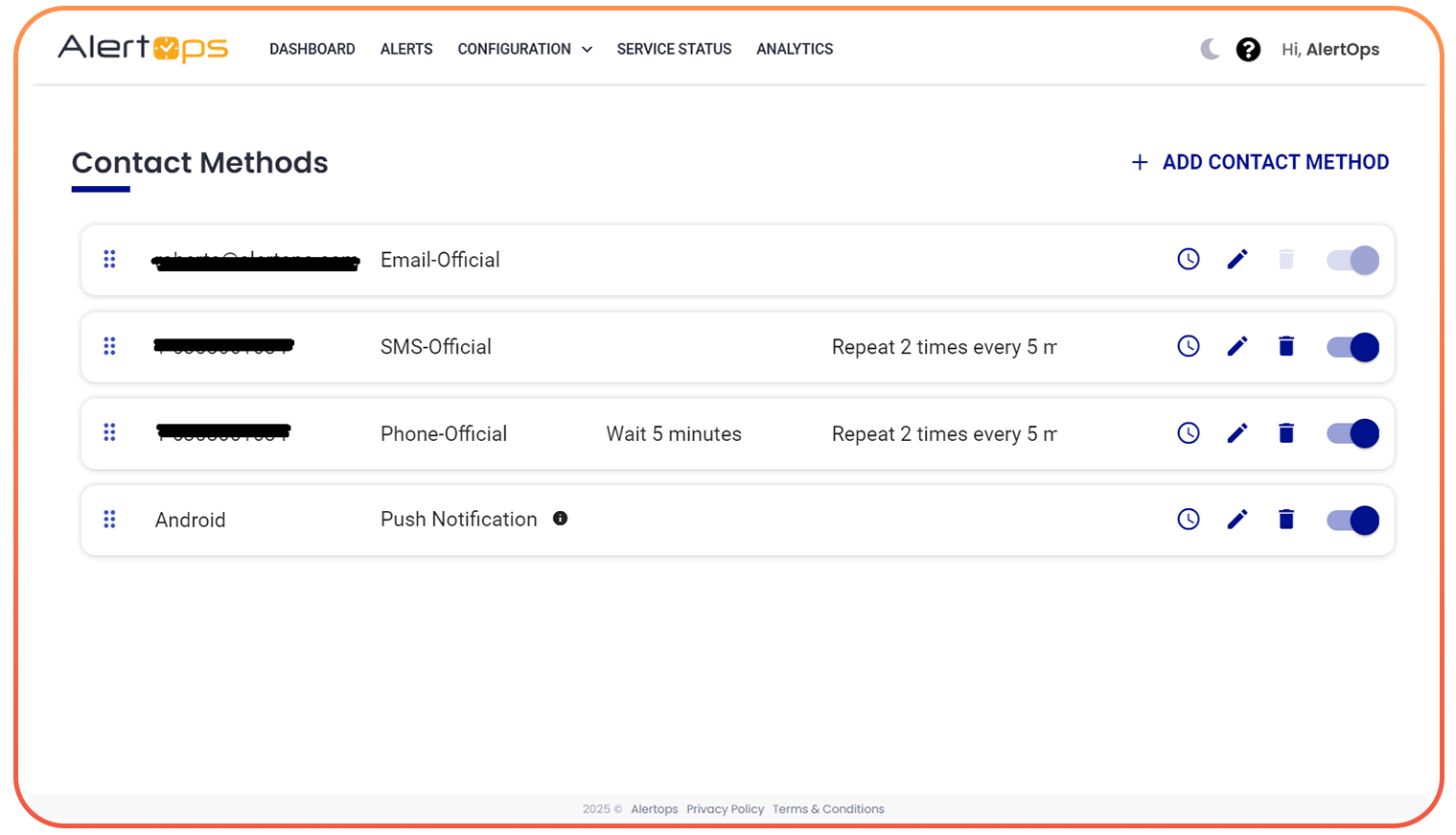
- Voice, SMS, push, email, Slack, and Teams configured per severity and role
- OpsIQ enriches every alert with root cause hint, historical match, and resolution suggestion
- Automated escalation until acknowledged no alert ever has no owner